Matrix factorization with explicit user and item bias, learning is performed by stochastic gradient descent More...
Public Member Functions | |
| override void | AddRatings (IRatings ratings) |
| Add new ratings and perform incremental training More... | |
| BiasedMatrixFactorization () | |
| Default constructor More... | |
| virtual bool | CanPredict (int user_id, int item_id) |
| Check whether a useful prediction (i.e. not using a fallback/default answer) can be made for a given user-item combination More... | |
| Object | Clone () |
| create a shallow copy of the object More... | |
| override float | ComputeObjective () |
| Compute the regularized loss More... | |
| override void | Iterate () |
| Run one iteration (= pass over the training data) More... | |
| override void | LoadModel (string filename) |
| Get the model parameters from a file More... | |
| override float | Predict (int user_id, int item_id) |
| Predict rating or score for a given user-item combination More... | |
| IList< Tuple< int, float > > | Recommend (int user_id, int n=-1, ICollection< int > ignore_items=null, ICollection< int > candidate_items=null) |
| Recommend items for a given user More... | |
| virtual System.Collections.Generic.IList< Tuple< int, float > > | Recommend (int user_id, int n=-1, System.Collections.Generic.ICollection< int > ignore_items=null, System.Collections.Generic.ICollection< int > candidate_items=null) |
| override void | RemoveItem (int item_id) |
| Remove all feedback by one item More... | |
| override void | RemoveRatings (IDataSet ratings) |
| Remove existing ratings and perform "incremental" training More... | |
| override void | RemoveUser (int user_id) |
| Remove all feedback by one user More... | |
| override void | RetrainItem (int item_id) |
| Updates the latent factors of an item More... | |
| override void | RetrainUser (int user_id) |
| Updates the latent factors on a user More... | |
| override void | SaveModel (string filename) |
| Save the model parameters to a file More... | |
| IList< Tuple< int, float > > | ScoreItems (IList< Tuple< int, float >> rated_items, IList< int > candidate_items) |
| Rate a list of items given a list of ratings that represent a new user More... | |
| override string | ToString () |
| Return a string representation of the recommender More... | |
| override void | Train () |
| Learn the model parameters of the recommender from the training data More... | |
| override void | UpdateRatings (IRatings ratings) |
| Update existing ratings and perform incremental training More... | |
Protected Member Functions | |
| override void | AddItem (int item_id) |
| override void | AddUser (int user_id) |
| double | ComputeLoss () |
| Computes the value of the loss function that is currently being optimized More... | |
| override float[] | FoldIn (IList< Tuple< int, float >> rated_items) |
| Compute parameters (latent factors) for a user represented by ratings More... | |
| override void | Iterate (IList< int > rating_indices, bool update_user, bool update_item) |
| Iterate once over rating data and adjust corresponding factors (stochastic gradient descent) More... | |
| float | Predict (int user_id, int item_id, bool bound) |
| override float | Predict (float[] user_vector, int item_id) |
| Predict rating for a fold-in user and an item More... | |
| void | SetupLoss () |
| Set up the common part of the error gradient of the loss function to optimize More... | |
| override void | UpdateLearnRate () |
| Updates current_learnrate after each epoch More... | |
Protected Attributes | |
| Func< double, double, float > | compute_gradient_common |
| delegate to compute the common term of the error gradient More... | |
| const int | FOLD_IN_BIAS_INDEX = 0 |
| Index of the bias term in the user vector representation for fold-in More... | |
| const int | FOLD_IN_FACTORS_START = 1 |
| Start index of the user factors in the user vector representation for fold-in More... | |
| float | global_bias |
| The bias (global average) More... | |
| double | last_loss = double.NegativeInfinity |
| Loss for the last iteration, used by bold driver heuristics More... | |
| float | max_rating |
| Maximum rating value More... | |
| float | min_rating |
| Minimum rating value More... | |
| float | rating_range_size |
| size of the interval of valid ratings More... | |
| IRatings | ratings |
| rating data More... | |
Properties | |
| float | BiasLearnRate [get, set] |
| Learn rate factor for the bias terms More... | |
| float | BiasReg [get, set] |
| regularization factor for the bias terms More... | |
| bool | BoldDriver [get, set] |
| Use bold driver heuristics for learning rate adaption More... | |
| float | Decay [get, set] |
| Multiplicative learn rate decay More... | |
| bool | FrequencyRegularization [get, set] |
| Regularization based on rating frequency More... | |
| double | InitMean [get, set] |
| Mean of the normal distribution used to initialize the factors More... | |
| double | InitStdDev [get, set] |
| Standard deviation of the normal distribution used to initialize the factors More... | |
| float | LearnRate [get, set] |
| Learn rate (update step size) More... | |
| OptimizationTarget | Loss [get, set] |
| The optimization target More... | |
| int | MaxItemID [get, set] |
| Maximum item ID More... | |
| virtual float | MaxRating [get, set] |
| Maximum rating value More... | |
| int | MaxThreads [get, set] |
| the maximum number of threads to use More... | |
| int | MaxUserID [get, set] |
| Maximum user ID More... | |
| virtual float | MinRating [get, set] |
| Minimum rating value More... | |
| bool | NaiveParallelization [get, set] |
| Use 'naive' parallelization strategy instead of conflict-free 'distributed' SGD More... | |
| uint | NumFactors [get, set] |
| Number of latent factors More... | |
| uint | NumIter [get, set] |
| Number of iterations over the training data More... | |
| virtual IRatings | Ratings [get, set] |
| The rating data More... | |
| float | RegI [get, set] |
| regularization constant for the item factors More... | |
| float | RegU [get, set] |
| regularization constant for the user factors More... | |
| override float | Regularization [set] |
| bool | UpdateItems [get, set] |
| bool | UpdateUsers [get, set] |
Detailed Description
Matrix factorization with explicit user and item bias, learning is performed by stochastic gradient descent
Per default optimizes for RMSE. Alternatively, you can set the Loss property to MAE or LogisticLoss. If set to log likelihood and with binary ratings, the recommender implements a simple version Menon and Elkan's LFL model, which predicts binary labels, has no advanced regularization, and uses no side information.
This recommender makes use of multi-core machines if requested. Just set MaxThreads to a large enough number (usually multiples of the number of available cores). The parallelization is based on ideas presented in the paper by Gemulla et al.
Literature:
- Ruslan Salakhutdinov, Andriy Mnih: Probabilistic Matrix Factorization. NIPS 2007. http://www.mit.edu/~rsalakhu/papers/nips07_pmf.pdf
- Steffen Rendle, Lars Schmidt-Thieme: Online-Updating Regularized Kernel Matrix Factorization Models for Large-Scale Recommender Systems. RecSys 2008. http://www.ismll.uni-hildesheim.de/pub/pdfs/Rendle2008-Online_Updating_Regularized_Kernel_Matrix_Factorization_Models.pdf
- Aditya Krishna Menon, Charles Elkan: A log-linear model with latent features for dyadic prediction. ICDM 2010. http://cseweb.ucsd.edu/~akmenon/LFL-ICDM10.pdf
- Rainer Gemulla, Peter J. Haas, Erik Nijkamp, Yannis Sismanis: Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent. KDD 2011. http://www.mpi-inf.mpg.de/~rgemulla/publications/gemulla11dsgd.pdf
This recommender supports incremental updates. See the paper by Rendle and Schmidt-Thieme.
Constructor & Destructor Documentation
|
inline |
Default constructor
Member Function Documentation
|
inlinevirtualinherited |
Add new ratings and perform incremental training
- Parameters
-
ratings the ratings
Reimplemented from IncrementalRatingPredictor.
|
inlinevirtualinherited |
Check whether a useful prediction (i.e. not using a fallback/default answer) can be made for a given user-item combination
It is up to the recommender implementor to decide when a prediction is useful, and to document it accordingly.
- Parameters
-
user_id the user ID item_id the item ID
- Returns
- true if a useful prediction can be made, false otherwise
Implements IRecommender.
Reimplemented in ExternalItemRecommender, ExternalRatingPredictor, BiPolarSlopeOne, SlopeOne, Constant, GlobalAverage, UserAverage, ItemAverage, and Random.
|
inlineinherited |
create a shallow copy of the object
|
inlineprotected |
Computes the value of the loss function that is currently being optimized
- Returns
- the loss
|
inlinevirtual |
Compute the regularized loss
- Returns
- the regularized loss
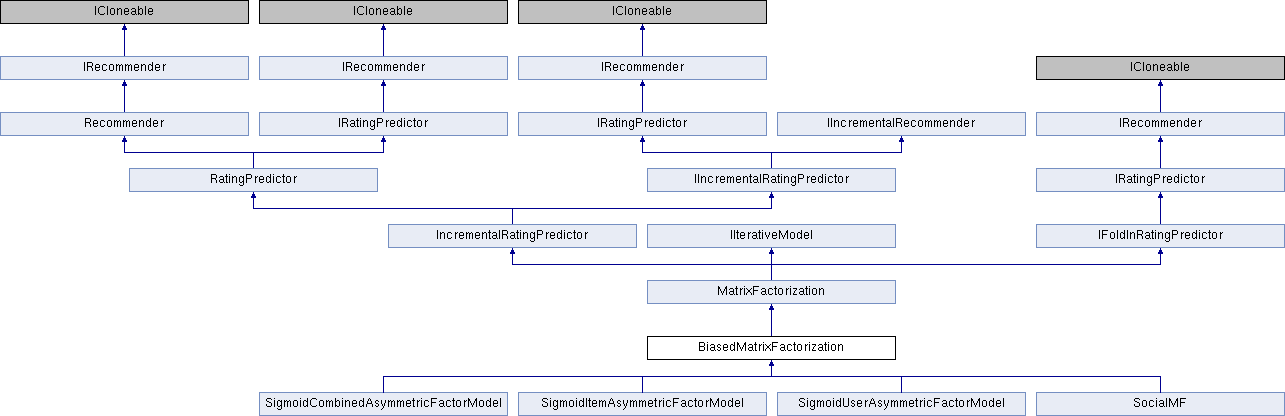
Reimplemented from MatrixFactorization.
Reimplemented in SigmoidCombinedAsymmetricFactorModel, SigmoidItemAsymmetricFactorModel, SigmoidUserAsymmetricFactorModel, and SocialMF.
|
inlineprotectedvirtual |
Compute parameters (latent factors) for a user represented by ratings
- Returns
- a vector of latent factors
- Parameters
-
rated_items a list of (item ID, rating value) pairs
Reimplemented from MatrixFactorization.
Reimplemented in SigmoidCombinedAsymmetricFactorModel, SigmoidUserAsymmetricFactorModel, and SigmoidItemAsymmetricFactorModel.
|
inlinevirtual |
Run one iteration (= pass over the training data)
Reimplemented from MatrixFactorization.
|
inlineprotectedvirtual |
Iterate once over rating data and adjust corresponding factors (stochastic gradient descent)
- Parameters
-
rating_indices a list of indices pointing to the ratings to iterate over update_user true if user factors to be updated update_item true if item factors to be updated
Reimplemented from MatrixFactorization.
Reimplemented in SigmoidCombinedAsymmetricFactorModel, SigmoidItemAsymmetricFactorModel, SigmoidUserAsymmetricFactorModel, and SocialMF.
|
inline |
Get the model parameters from a file
- Parameters
-
filename the name of the file to read from
Implements IRecommender.
|
inline |
Predict rating or score for a given user-item combination
- Parameters
-
user_id the user ID item_id the item ID
- Returns
- the predicted score/rating for the given user-item combination
Implements IRecommender.
|
inlineprotectedvirtual |
Predict rating for a fold-in user and an item
- Parameters
-
user_vector a float vector representing the user item_id the item ID
- Returns
- the predicted rating
Reimplemented from MatrixFactorization.
Reimplemented in SigmoidCombinedAsymmetricFactorModel.
|
inherited |
Recommend items for a given user
- Parameters
-
user_id the user ID n the number of items to recommend, -1 for as many as possible ignore_items collection if items that should not be returned; if null, use empty collection candidate_items the candidate items to choose from; if null, use all items
- Returns
- a sorted list of (item_id, score) tuples
Implemented in WeightedEnsemble, and Ensemble.
|
inlinevirtual |
Remove all feedback by one item
- Parameters
-
item_id the item ID
Reimplemented from IncrementalRatingPredictor.
|
inlinevirtualinherited |
Remove existing ratings and perform "incremental" training
- Parameters
-
ratings the user and item IDs of the ratings to be removed
Reimplemented from IncrementalRatingPredictor.
|
inlinevirtual |
Remove all feedback by one user
- Parameters
-
user_id the user ID
Reimplemented from IncrementalRatingPredictor.
|
inlinevirtual |
Updates the latent factors of an item
- Parameters
-
item_id the item ID
Reimplemented from MatrixFactorization.
|
inlinevirtual |
Updates the latent factors on a user
- Parameters
-
user_id the user ID
Reimplemented from MatrixFactorization.
|
inline |
Save the model parameters to a file
- Parameters
-
filename the name of the file to write to
Implements IRecommender.
|
inlineinherited |
Rate a list of items given a list of ratings that represent a new user
- Returns
- a list of int and float pairs, representing item IDs and predicted ratings
- Parameters
-
rated_items the ratings (item IDs and rating values) representing the new user candidate_items the items to be rated
Implements IFoldInRatingPredictor.
|
inlineprotected |
Set up the common part of the error gradient of the loss function to optimize
|
inline |
Return a string representation of the recommender
The ToString() method of recommenders should list the class name and all hyperparameters, separated by space characters.
Implements IRecommender.
|
inline |
Learn the model parameters of the recommender from the training data
Implements IRecommender.
|
inlineprotectedvirtual |
Updates current_learnrate after each epoch
Reimplemented from MatrixFactorization.
|
inlinevirtualinherited |
Update existing ratings and perform incremental training
- Parameters
-
ratings the ratings
Reimplemented from IncrementalRatingPredictor.
Member Data Documentation
|
protected |
delegate to compute the common term of the error gradient
|
protected |
Index of the bias term in the user vector representation for fold-in
|
protected |
Start index of the user factors in the user vector representation for fold-in
|
protectedinherited |
The bias (global average)
|
protected |
Loss for the last iteration, used by bold driver heuristics
|
protectedinherited |
Maximum rating value
|
protectedinherited |
Minimum rating value
|
protected |
size of the interval of valid ratings
|
protectedinherited |
rating data
Property Documentation
|
getset |
Learn rate factor for the bias terms
|
getset |
regularization factor for the bias terms
|
getset |
Use bold driver heuristics for learning rate adaption
Literature:
- Rainer Gemulla, Peter J. Haas, Erik Nijkamp, Yannis Sismanis: Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent. KDD 2011. http://www.mpi-inf.mpg.de/~rgemulla/publications/gemulla11dsgd.pdf
|
getsetinherited |
Multiplicative learn rate decay
Applied after each epoch (= pass over the whole dataset)
|
getset |
Regularization based on rating frequency
Regularization proportional to the inverse of the square root of the number of ratings associated with the user or item. As described in the paper by Menon and Elkan.
|
getsetinherited |
Mean of the normal distribution used to initialize the factors
|
getsetinherited |
Standard deviation of the normal distribution used to initialize the factors
|
getsetinherited |
Learn rate (update step size)
|
getset |
The optimization target
|
getsetinherited |
Maximum item ID
|
getsetinherited |
Maximum rating value
|
getset |
the maximum number of threads to use
For parallel learning, set this number to a multiple of the number of available cores/CPUs
|
getsetinherited |
Maximum user ID
|
getsetinherited |
Minimum rating value
|
getset |
Use 'naive' parallelization strategy instead of conflict-free 'distributed' SGD
The exact sequence of updates depends on the thread scheduling. If you want reproducible results, e.g. when setting –random-seed=N, do NOT set this property.
|
getsetinherited |
Number of latent factors
|
getsetinherited |
Number of iterations over the training data
|
getset |
regularization constant for the item factors
|
getset |
regularization constant for the user factors
The documentation for this class was generated from the following file:
- BiasedMatrixFactorization.cs
